

How and why Git Works

H
CS Graduate | Technical Writing | Software development | 50K+ impressions
Search for a command to run...
No comments yet. Be the first to comment.
These are the assignments or knowledge dumps I decide to write for the "Chai aur Code's web Dev Cohort 2026"
If you’ve spent any time working on computers, you have probably used manual version control. It usually looks like this: website_v1 website_v2_final website_v2_final_FOR_REAL website_v2_final_USE_THI
RAG helps LLMs answer questions using your own data, but it doesn't guarantee correct answers. Here's how the pipeline works and where it commonly breaks down.

Imagine asking an AI, "Write a blog," versus "Act as an SEO expert and write a 1,000-word blog on AI safety formatted in markdown." The difference in the resulting output is night and day. A prompt is

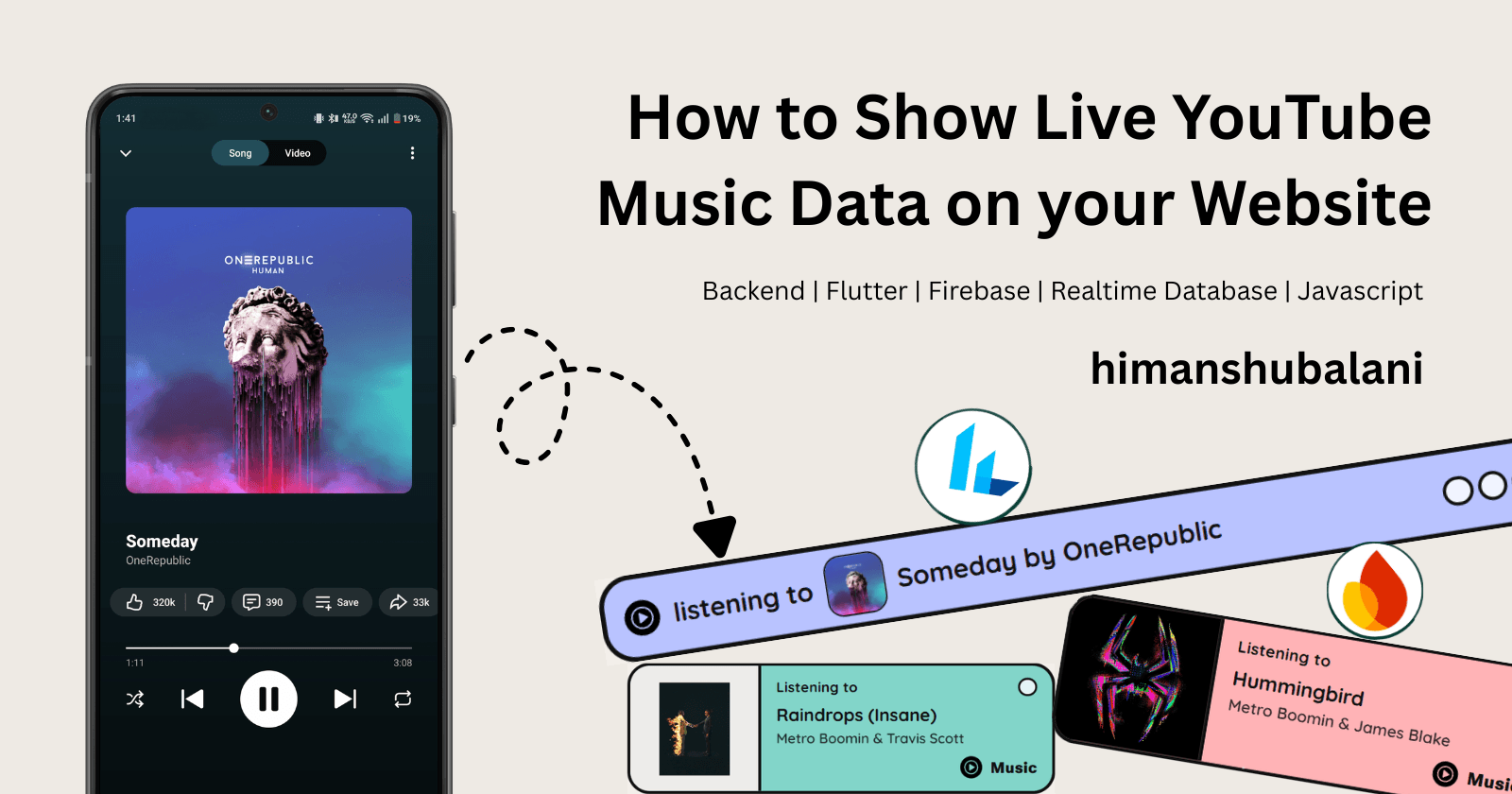
Spotify and Apple Music make it incredibly easy to showcase your live listening habits on your website. YouTube Music? Not so much. After doing some setup you can do an API call and fetch your account
Arthur C. Clarke's famous third law: "Any sufficiently advanced technology is indistinguishable from magic" perfectly captures how the pace of human innovation works. From carrying supercomputers in o

Why HTTP is amnesiac, the difference between transport and state, and how to choose the right auth strategy for your Node.js app.
I spent my first two years as a developer not looking for a duel with Git.
Like a lot of people, I treated it as a magic save button. I memorized the golden path - git status ,git add. , git commit, git push and prayed I never accidentally typed git rebase or got stuck in a detached HEAD state by git pull. One time when things inevitably broke, I copied my project folder to my desktop, delete the original, re-clone the repository, and manually paste my changed files back in.
I did this because I had a fundamentally flawed mental model of what Git actually is. I thought it was a complex tracking system logging a chronological list of changes, line by line.
It isn’t. Git is much simpler than that. At its core, Git is just a key-value data store built on top of a graph. And all of that data, every branch, every commit, every file lives right inside your project in a hidden directory called .git.
If you want to stop fighting Git and start using it confidently, you don't need to memorize more commands. You just need to look inside the .git folder and understand how it stores your code.
.git Directory: The Hidden DatabaseWhen you run git init in a new project, Git doesn't install a background service or hook into your operating system. It simply creates a hidden folder named .git.
If you delete this folder, your files remain exactly as they are in your working directory, but your project is no longer a Git repository. You lose your history, your branches, and your commits. That’s because the .git folder is the database.
If you poke around inside a fresh .git directory (ls -la .git), you'll see a few things, but the three most important are:
HEAD: A text file indicating which branch you are currently on.
refs/: A directory that stores pointers to your branches and tags.
objects/: The database itself. This is where your actual code and history live.
To understand Git, we have to understand what goes into the objects directory.
Before we look at the objects themselves, we need to understand how Git labels them.
Git is a content-addressable filesystem. In a normal filesystem, you find a file by its name and path (e.g., src/main.js). In Git, you find data by a hash of its contents.
When you hand data to Git, it runs that data through a hashing algorithm (SHA-1) to generate a 40-character hexadecimal string. That string becomes the "key," and the file contents become the "value."
This is good design for two reasons:
Integrity: If a single byte of a file changes, the hash changes completely. It is mathematically impossible for a file to be silently corrupted or altered without Git noticing, because the hash wouldn't match the content.
Deduplication: If you have two identical images in different folders, Git only stores the image once. Because the contents are identical, the hash is identical.
Git stores everything in the objects/ directory using just three primary types of objects.
When you track a file in Git, it compresses the contents of that file and stores it as a blob (Binary Large Object).
Here is the most important thing to understand about blobs: they do not store filenames. A blob is purely the content of the file. If you rename a file without changing its text, Git doesn't create a new blob. It just updates the pointer to the existing one.
If blobs are the file contents, trees are the directories. A tree object solves the problem of filenames. It is essentially a list of pointers. It contains the names of files and directories, and points to the SHA-1 hashes of the corresponding blobs or other sub-trees.
A commit is the metadata wrapper. It points to the top-level root tree of your project at an exact moment in time. It also contains the author's name, the timestamp, the commit message, and critically, a pointer to its parent commit(s).
This is the mental model diagram you should keep in your head:
[Commit: 8f3a...] <--Knows who, when, why, and the parent commit
|
v
[Tree: 5c2b...] <-- Knows the folder structure and filenames
|
|-- "readme.md" --> [Blob: 98ea...] <--Knows the text
|
|-- "src/" -->[Tree: 4b1c...] <-- A sub-directory
Notice something important here: Git does not store "diffs" or deltas. When you make a commit, Git saves a complete snapshot of your entire project. If a file hasn't changed since the last commit, Git doesn't copy the file again, it just links the new tree to the exact same blob hash from the previous commit.
add and commit when you workLet’s step away from theory and watch Git do its job. Imagine we initialize a fresh repository.
$ mkdir git-test && cd git-test
$ git init
We create a new file:
$ echo "Hello Hashnode" > greeting.txt
At this point, Git knows nothing about this file. It exists in our working directory, but the .git/objects folder is completely empty.
git add?$ git add greeting.txt
When you run git add, two things happen internally:
Git takes the contents of greeting.txt ("Hello Hashnode"), compresses it, and writes it to the .git/objects directory as a blob.
It updates a hidden file called the index (which is what we call the "staging area"). The index now knows that the file greeting.txt corresponds to the hash of that new blob.
We can prove this. If we look in the .git/objects directory right now before we even commit, there is a file in there.
$ find .git/objects -type f
.git/objects/a5/c19667710254f835085b99ce2665b2a4392942
We can use Git's plumbing command cat-file to peek inside that hash:
$ git cat-file -p a5c19667710254f835085b99ce2665b2a4392942
Hello Hashnode
The data is already saved. git add is what actually writes your file contents into Git's database.
git commit?$ git commit -m "Initial commit"
When we run git commit, Git reads the staging area (the index) and does the following:
It creates a tree object representing the current state of our directory structure, pointing to our blob.
It creates a commit object. This commit points to the tree we just made, adds our "Initial commit" message, and attaches our author info.
It updates HEAD (usually via a branch reference like main) to point to the new commit hash.
If we look at our objects folder now, we have three items: the blob, the tree, and the commit.
Once you realize that Git is just a web of commits pointing to trees, and trees pointing to blobs, the terrifying parts of Git start to dissolve.
Why is checking out branches so fast? Because checking out a branch doesn't require Git to calculate thousands of file diffs. A branch is literally just a tiny text file inside .git/refs/heads/ that contains a 40-character commit hash. When you switch branches, Git just looks at the root tree of that commit and swaps your working directory to match the blobs it points to.
What does git reset --hard actually do? It just takes your branch pointer, moves it to an older commit hash, and overwrites your working directory to match that older tree. The newer commits aren't immediately deleted—they still live in .git/objects until Git runs its internal garbage collection. (This is why you can almost always recover "lost" commits using git reflog).
You don't need to manually inspect the .git folder in your day-to-day work. But understanding that it is a snapshot-based, content-addressable key-value store changes how you interact with it.
Git isn't a fragile ledger of changes that you might break. It’s a robust, immutable database of snapshots. Once you trust the graph, you stop fearing the tools.