

How the Internet Routes Your Requests with DNS

H
CS Graduate | Technical Writing | Software development | 50K+ impressions
Search for a command to run...
No comments yet. Be the first to comment.
These are the assignments or knowledge dumps I decide to write for the "Chai aur Code's web Dev Cohort 2026"
Learning A, CNAME, MX, and TXT records by looking inside a real developer’s domain configuration.
RAG helps LLMs answer questions using your own data, but it doesn't guarantee correct answers. Here's how the pipeline works and where it commonly breaks down.

Imagine asking an AI, "Write a blog," versus "Act as an SEO expert and write a 1,000-word blog on AI safety formatted in markdown." The difference in the resulting output is night and day. A prompt is

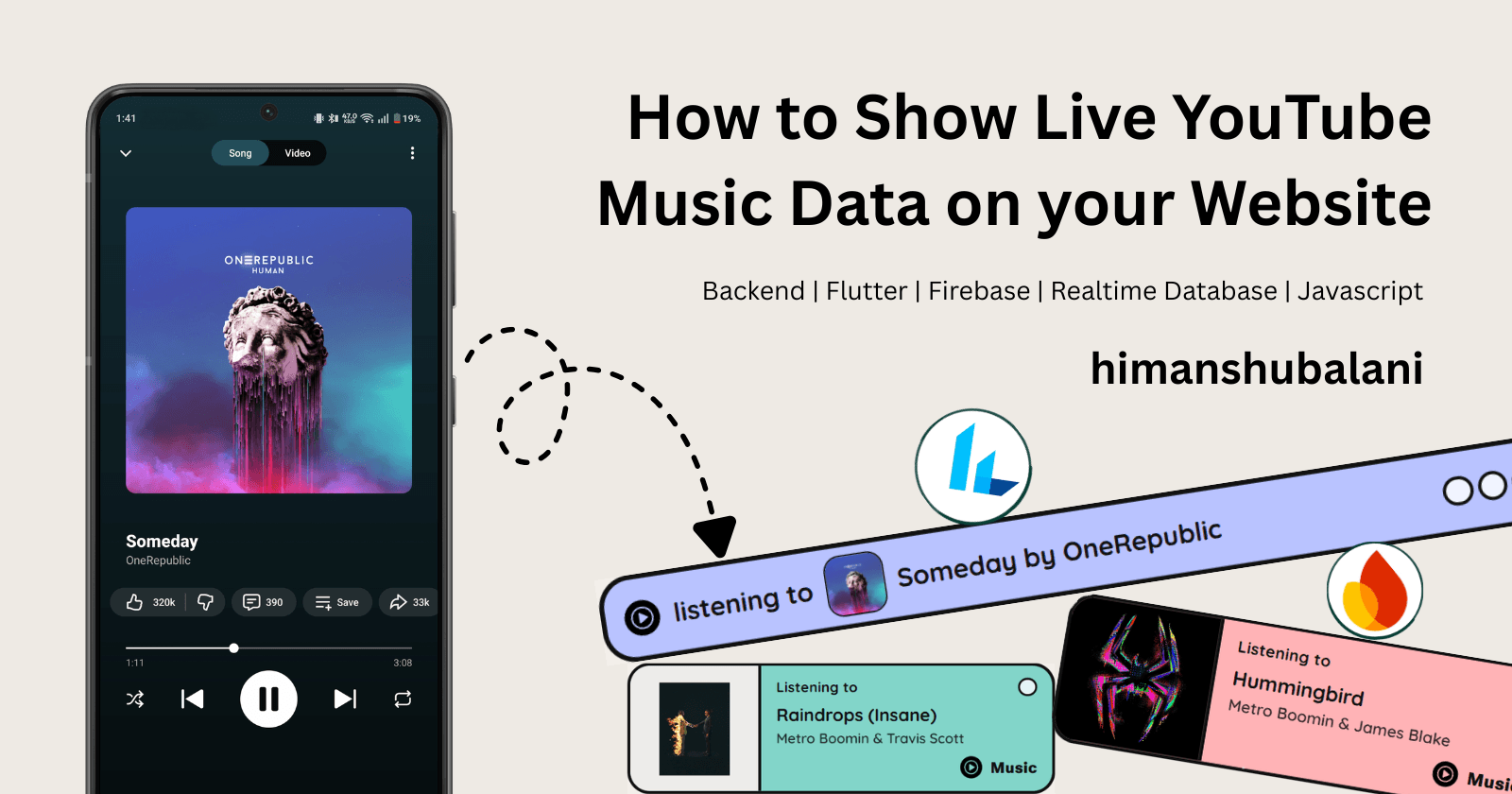
Spotify and Apple Music make it incredibly easy to showcase your live listening habits on your website. YouTube Music? Not so much. After doing some setup you can do an API call and fetch your account
Arthur C. Clarke's famous third law: "Any sufficiently advanced technology is indistinguishable from magic" perfectly captures how the pace of human innovation works. From carrying supercomputers in o

Why HTTP is amnesiac, the difference between transport and state, and how to choose the right auth strategy for your Node.js app.
If I tell you to navigate to 142.250.190.46, you probably have no idea what website you are about to load. If I tell you to go to google.com, you know exactly where you are going.
Humans are good at remembering names. Computers are only good at routing numbers (IP addresses).
The Domain Name System (DNS) is the bridge between the two. You will often hear DNS described as "the phonebook of the internet." That is a helpful starting point, but as a developer, it obscures the actual engineering. DNS is not a single file or a central server. It is a globally distributed, highly available, hierarchical database.
To understand how it works, we aren't going to read the specification. We are going to query the database ourselves using a command-line tool called dig.
When you type a URL into your browser, your computer doesn't instantly know where to send the network request. It hands the domain name off to a Recursive Resolver (usually a server operated by your Internet Service Provider, or a public one like Google's 8.8.8.8).
The Recursive Resolver's job is to hunt down the IP address on your behalf. To do this, it traverses three distinct layers of the DNS hierarchy:
Root Name Servers: The starting point. They know where to find the servers for top-level extensions (like .com or .org).
TLD Name Servers: The Top-Level Domain servers. They know who owns a specific domain name.
Authoritative Name Servers: The final destination. They hold the actual IP address for the specific domain.
Browser --> Recursive Resolver
|
+--> 1. Asks Root Server
+--> 2. Asks TLD Server (.com)
+--> 3. Asks Authoritative Server (google.com)
|
Browser <--- Returns IP Address
Let's step into the shoes of the Recursive Resolver and do this manually.
dig . NS)Every journey on the internet begins at the root. In DNS, the root is literally represented by a single dot (.). You don't usually type it, but the fully qualified domain name for Google is actually google.com..
We can use the dig command (Domain Information Groper) to ask the DNS system questions. Let's ask for the NS (Name Server) records for the root. An NS record simply says: "I don't necessarily have the IP address you want, but here is the server who manages this zone."
Open your terminal and type:
dig . NS +short
(Note: The +short flag just cleans up the output so we only see the answers).
Output:
a.root-servers.net.
b.root-servers.net.
c.root-servers.net.
...
There are 13 logical root server addresses, managed by organizations around the world. When our Recursive Resolver starts its hunt for google.com, it randomly picks one of these root servers and says: "Hey, do you know the IP address for google.com?"
The root server replies: "No, but I see it ends in .com. Go ask the .com servers. Here is their address."
dig com. NS)Now we move down a level in the hierarchy. We know we need to talk to the servers that manage the .com Top-Level Domain. Let's query them:
dig com. NS +short
Output:
a.gtld-servers.net.
b.gtld-servers.net.
c.gtld-servers.net.
...
These are the TLD name servers for .com (operated by a company called Verisign).
Our Recursive Resolver goes to one of these gtld-servers and says: "Hey, the root server sent me. Do you have the IP address for google.com?"
The TLD server replies: "No, my job is just to keep track of who bought which .com domains. I see Google bought google.com. I don't know their exact server IPs, but here are the specific Name Servers that Google's engineers set up."
dig google.com NS)We are almost there. The TLD server gave us a referral to the Authoritative Name Servers for google.com. Let's see what those are:
dig google.com NS +short
Output:
ns1.google.com.
ns2.google.com.
ns3.google.com.
ns4.google.com.
These servers belong to Google. They are "authoritative"—meaning whatever answer they give is the absolute, final truth for this domain. No more passing the buck.
Our Recursive Resolver connects to ns1.google.com and says: "Okay, the root sent me to the TLD, the TLD sent me to you. What is the IP address for google.com?"
dig google.com)When we want an actual IP address (IPv4), we ask for an A record (Address record). If we run dig without specifying the record type, it defaults to asking for the A record.
dig google.com +short
Output:
142.250.190.46
We found it.
The Recursive Resolver takes this IP address, runs back to your computer, and hands it to the browser. Your browser then initiates a TCP handshake with 142.250.190.46, sends an HTTP GET request, and finally downloads the Google homepage.
You might look at this process and think: That seems incredibly slow. Three separate server trips just to figure out where to send the real request?
There are two reasons this design is necessary:
Scale and Decentralization: If one central server held every IP address for every website, it would be a massive single point of failure and would crumble under the traffic of the global internet. Delegating authority (Root -> TLD -> Authoritative) means the load is distributed across millions of servers.
Caching: In reality, your computer doesn't do this full trip every time. When the Recursive Resolver finds the IP for google.com, it caches (memorizes) that answer for a certain amount of time (the "Time to Live" or TTL). The next time you ask, it just gives you the cached IP instantly.
The next time a website won't load, or a domain migration is taking hours to process, you won't have to guess what's happening. You know exactly what DNS is doing, and you have the dig command to prove it.